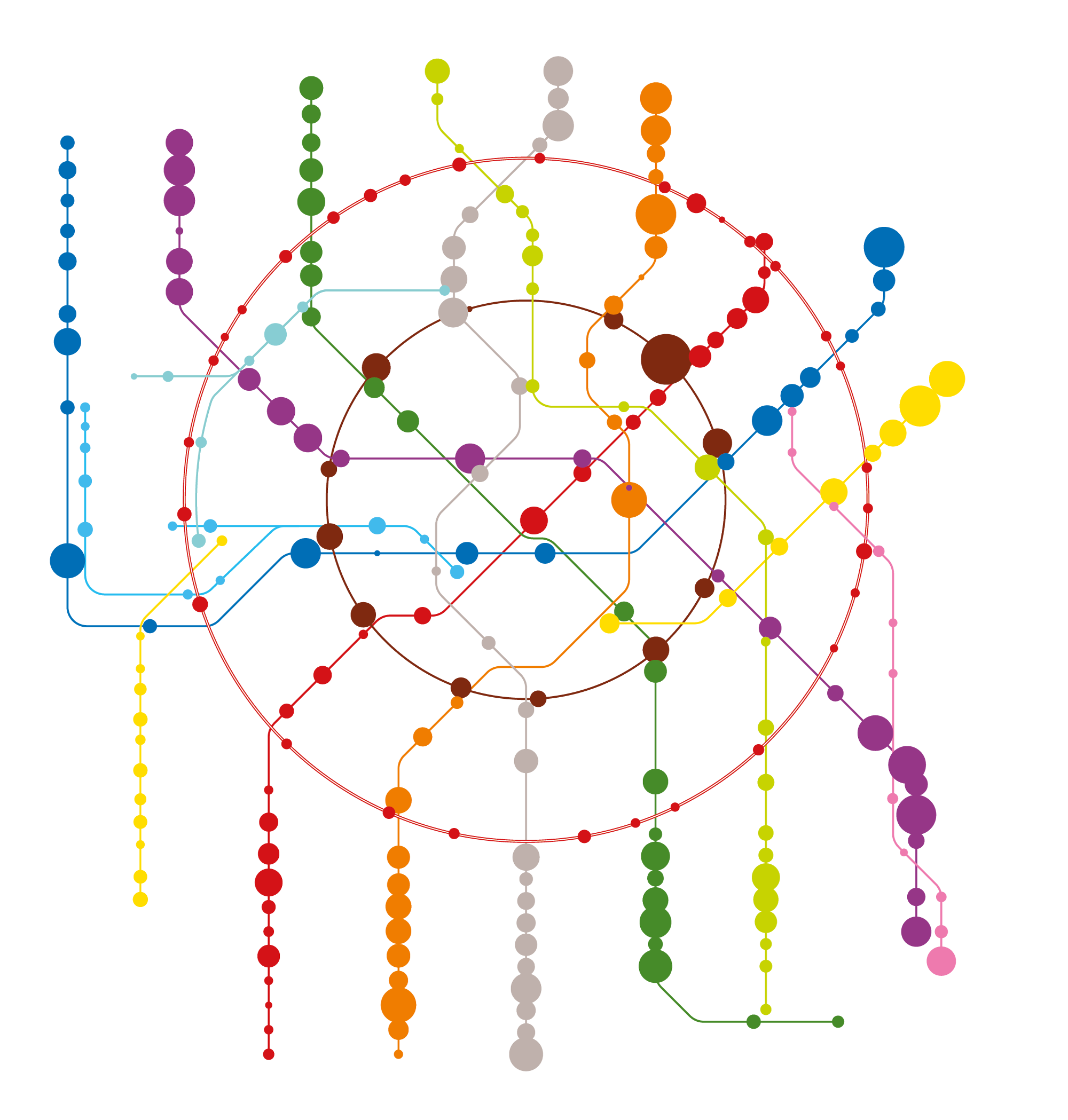
Тысячи пассажиров метро
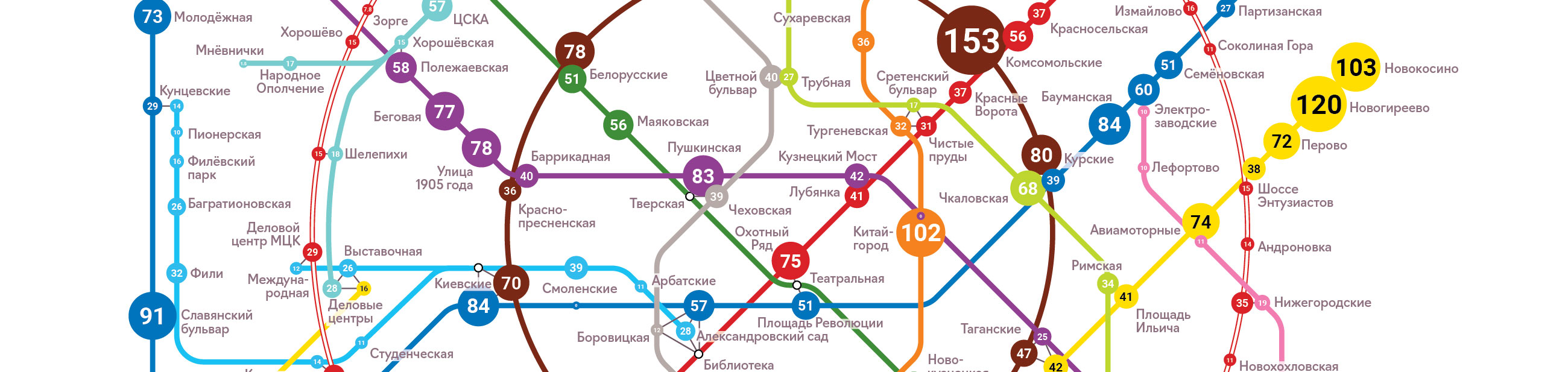
Подготовка макета
На самом деле, это было самым сложным этапом, потому что не было готовой схемы метро в нужном виде. Но по этой же причине схема стала оригинальной.
На Портале данных по пассажиропотоку станций указаны значения только для метро, включая МЦК, но без новой БКЛ и без Диаметров. Поэтому взял самую крутую схему для Москвы от Студии Артемия Лебедева. 😉
Схему обрисовал с упрощениями: без Диаметров, иконок, маршрутов других видов транспорта. Некоторые узлы и линии перенёс, потому что освободилось место. Пересадки обозначил серыми полосочками, потому что они не важны.
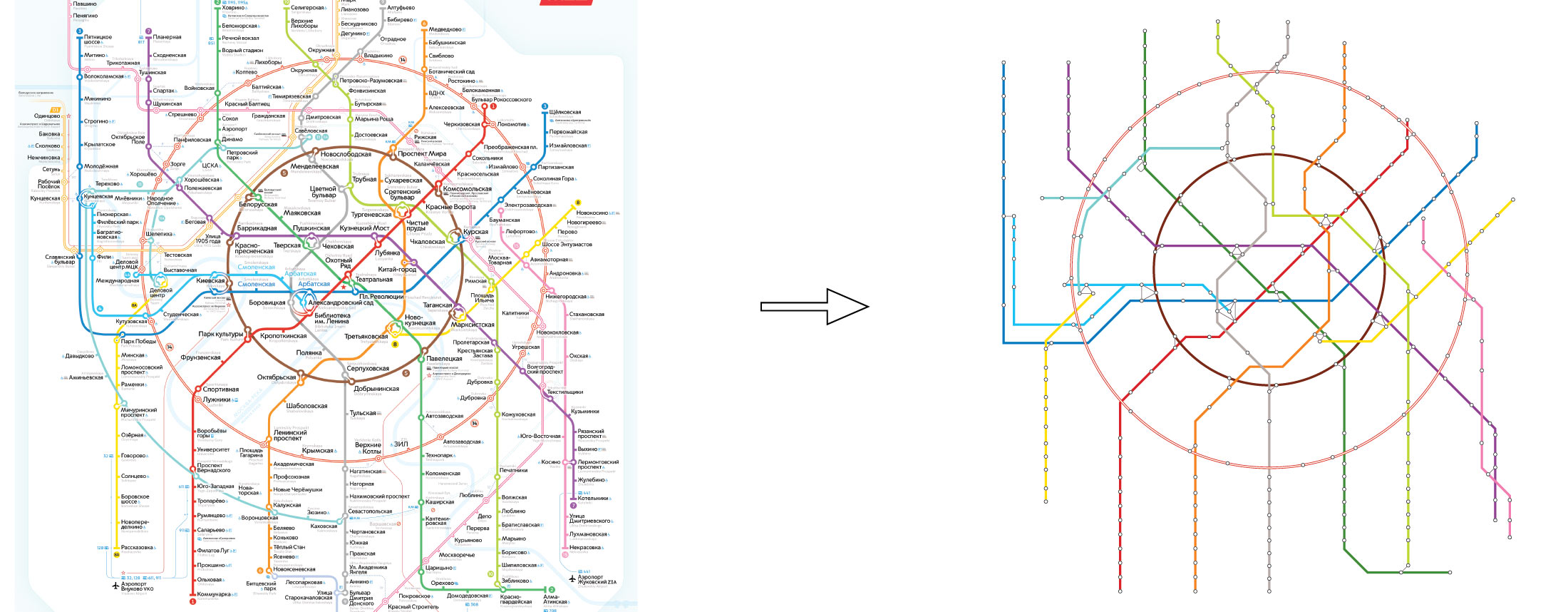
Так как схема метро будет для информации, а не не для навигации, решил не дублировать названия одинаковых станций, а написать названия станций во множественном числе. Это сэкономило место, а меньшее число текстов улучшило внимание на числа пассажиров. Плюс — подчёркивалось наличие двух, а иногда и трёх станций с одинаковыми названиями.
😎 А главное — такого нигде ещё не было.
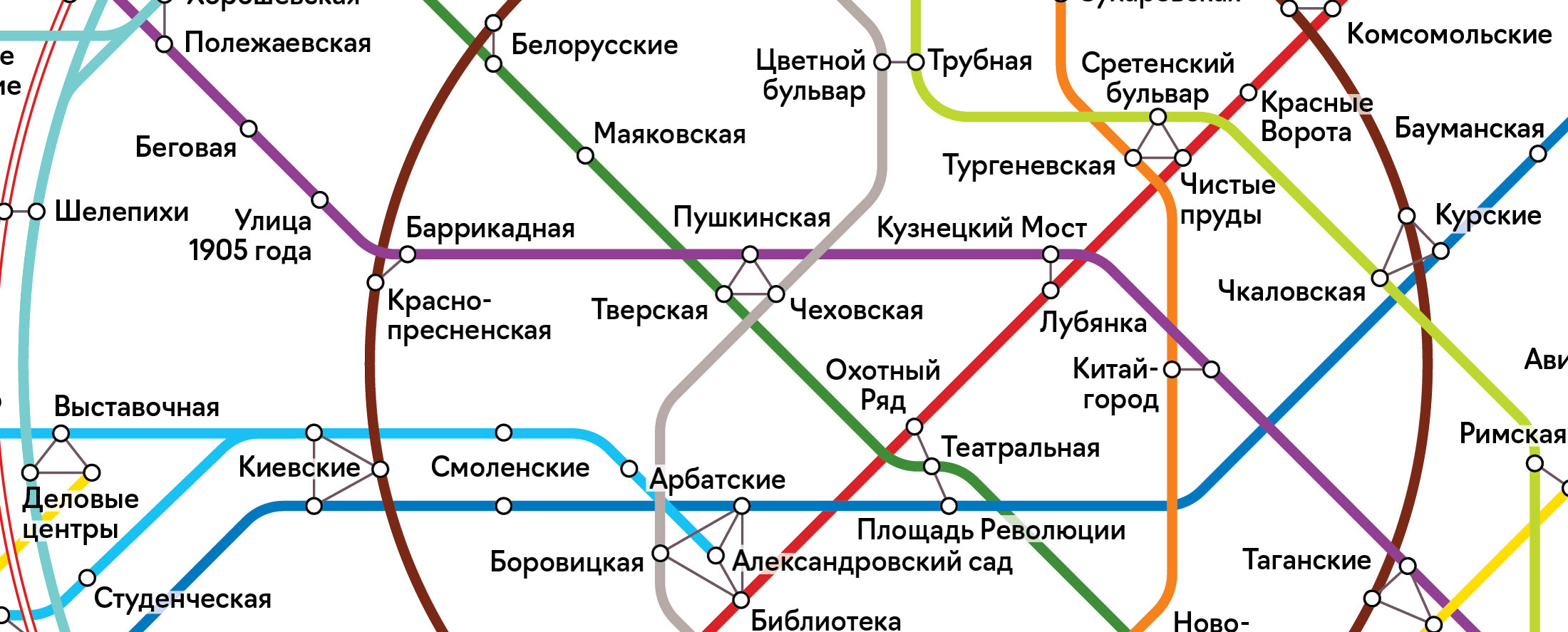
Так как схему будет обрабатывать скрипт, то все станции были обозначены маркерами, вместо которых потом будут рисоваться круги и цифры. Названия всех станций тоже, конечно, пришлось переносить руками, потому что их размещение будет меняться из-за выравнивания по разным размерам станций (в зависимости от числа пассажиров).
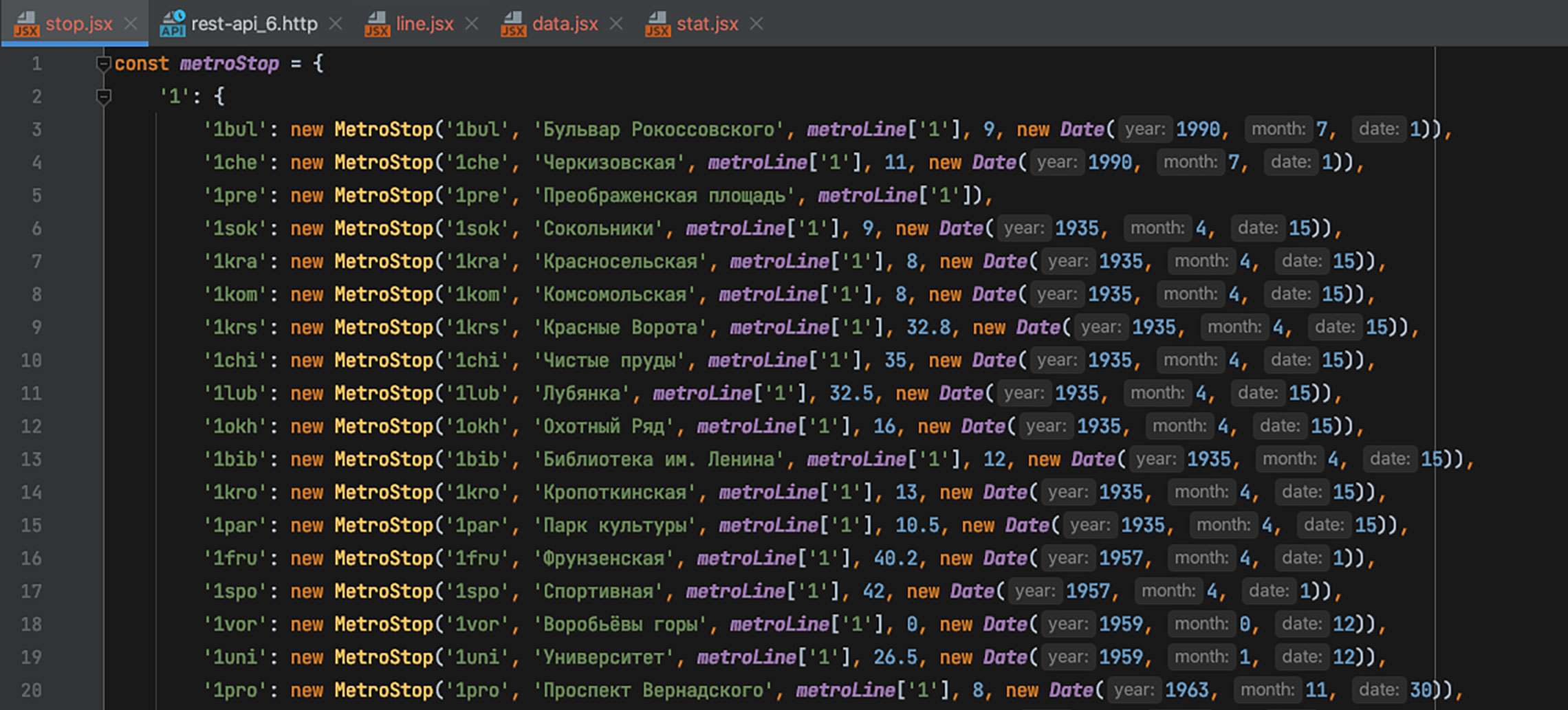
Каждому маркеру станции нужно было дать уникальное имя. Я просто назвал их цифрой линии + 3 буквы латиницей. Такой же уникальный ключ станции должен быть и в будущих данных.
На картинке ниже видно выделенную станцию «Косино» и её имя в списке объектов Иллюстратора — 15kos.

Подготовка данных
😢 Стоит признать, что данные Портал выдаёт не в самом лучшем виде.
Первая проблема — путаница с е/ё (отличия от названий на всех схемах и во всех носителях). Где-то «ё» стоит, где-то «е». У Савёловской вообще путаница: на одной ветке пишется через «ё», на другой — «е».
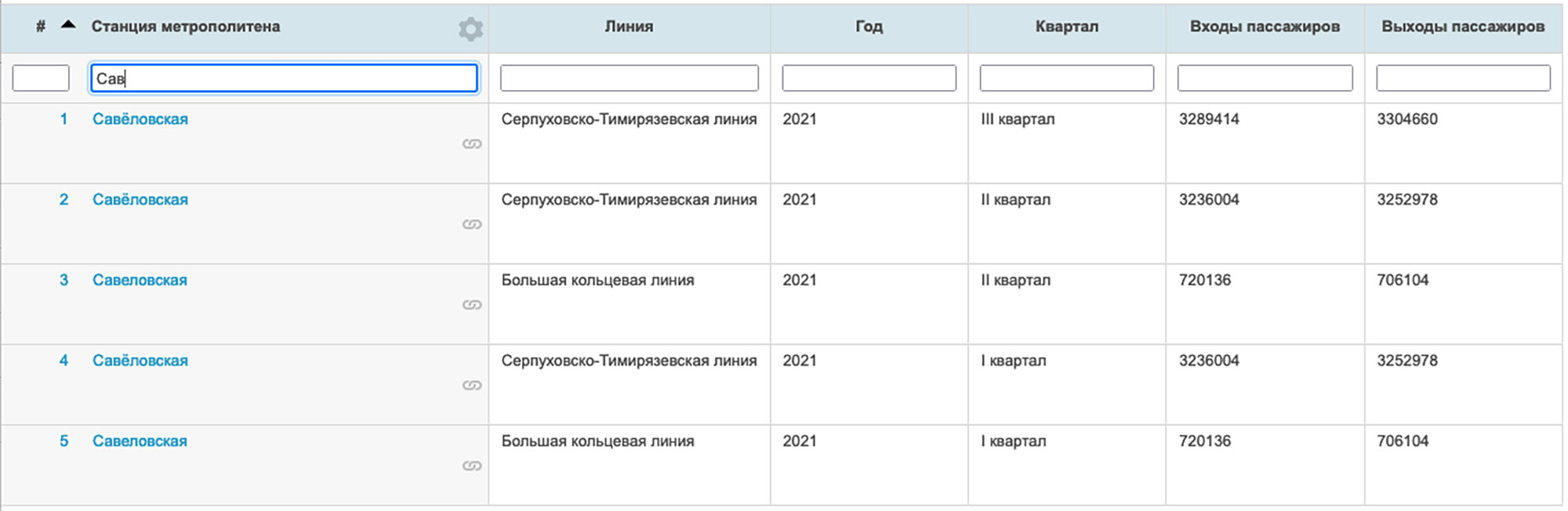
Больших букв в исторических названиях вообще нет: «Октябрьское поле», «Кузнецкий мост» и так далее. «Охотный ряд», например, в итоге привёл к ошибке в первой опубликованной версии схемы (эта ошибка, кстати, оказалась единственной, но об этом позже).
Всё это не критичные ошибки, просто потребовали дополнительных действий. Главная проблема — наличие одинаковых данных по 1-му и 2-му кварталу! Я назвал их «аномалиями» и написал об этом в легенде схемы. Надеюсь, в следующих кварталах эти неточности исправят.
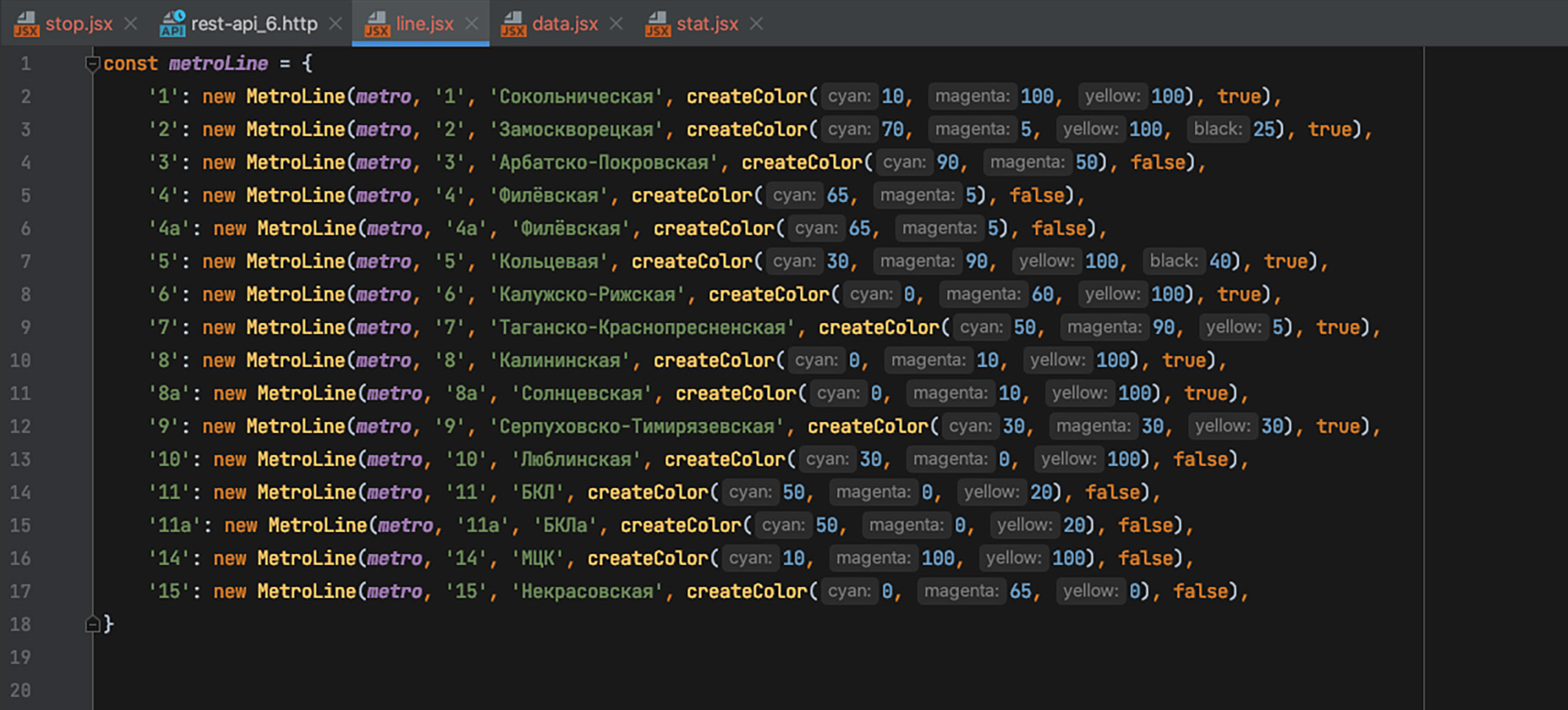
Объектная модель линий и станций, а также все данные по ним: цвета, связность, уникальные ключи станций, по которым необходимо искать соответствующие маркеры на макете — у меня были. Поэтому тут всё прошло быстро.
Скрипт для Иллюстратора
Сам скрипт для Иллюстратора был очень простым: надо было перебрать линии метро, перебрать на них станции, взять маркер станции на схеме, рассчитать коэффициент увеличения круга и размера шрифта и покрасить в цвет линии. На жёлтых линиях дополнительно покрасить цифры в чёрный цвет.
В конце скрипт выводит не найденные станции в исходных данных, статистику по всем линиям и суммарную по всему метро.
замедленная съёмка
И после генерации нужно было немного подвигать названия, круги и белые подложки в результате, потому что размеры станций увеличились. Ниже на картинке всё сгенерированное и результат — видны небольшие смещения у больших кругов самых нагруженных станций:
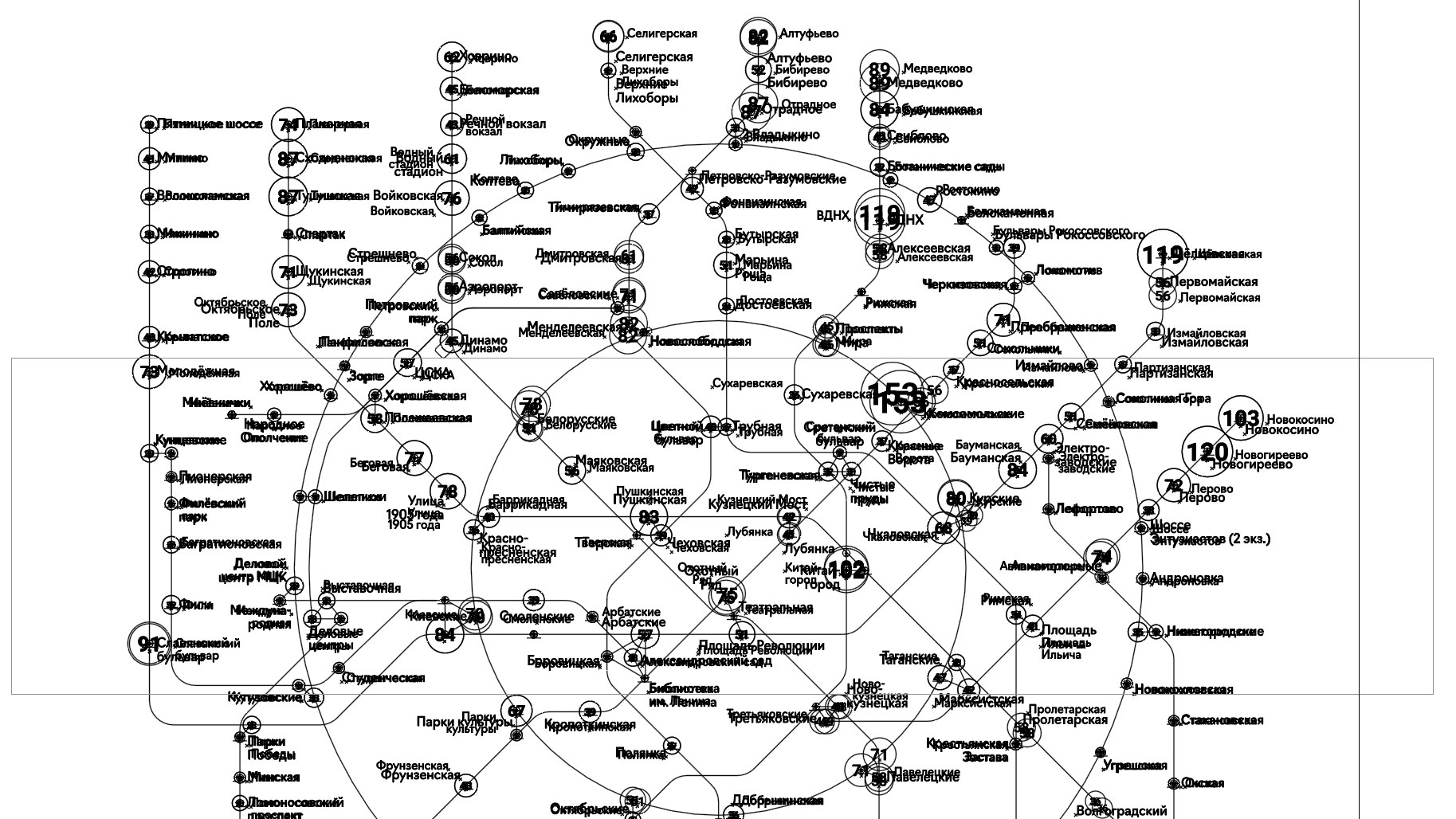
Готово!
Легенда:
Пока делал легенду, появилась мысль изобразить суммарные пассажирские потоки по линиям и по всем станциям. Первая мысль, конечно, была написать список линий и указать числа. Но это казалось скучным. поэтому придумался вот такой «гамбургер» из линий, соответствующей ширины.
Проблема была с жёлтой, вернее с жёлтыми линиями: если их класть друг на друга, то они сливаются. Если рядом, то неправильно ощущается масштаб по высоте. Поэтому появилось решение с двумя разными слоями по сторонам, и с разрывом по середине. По идее, такой разрыв и есть на этой линии...

Долгожданный результат:
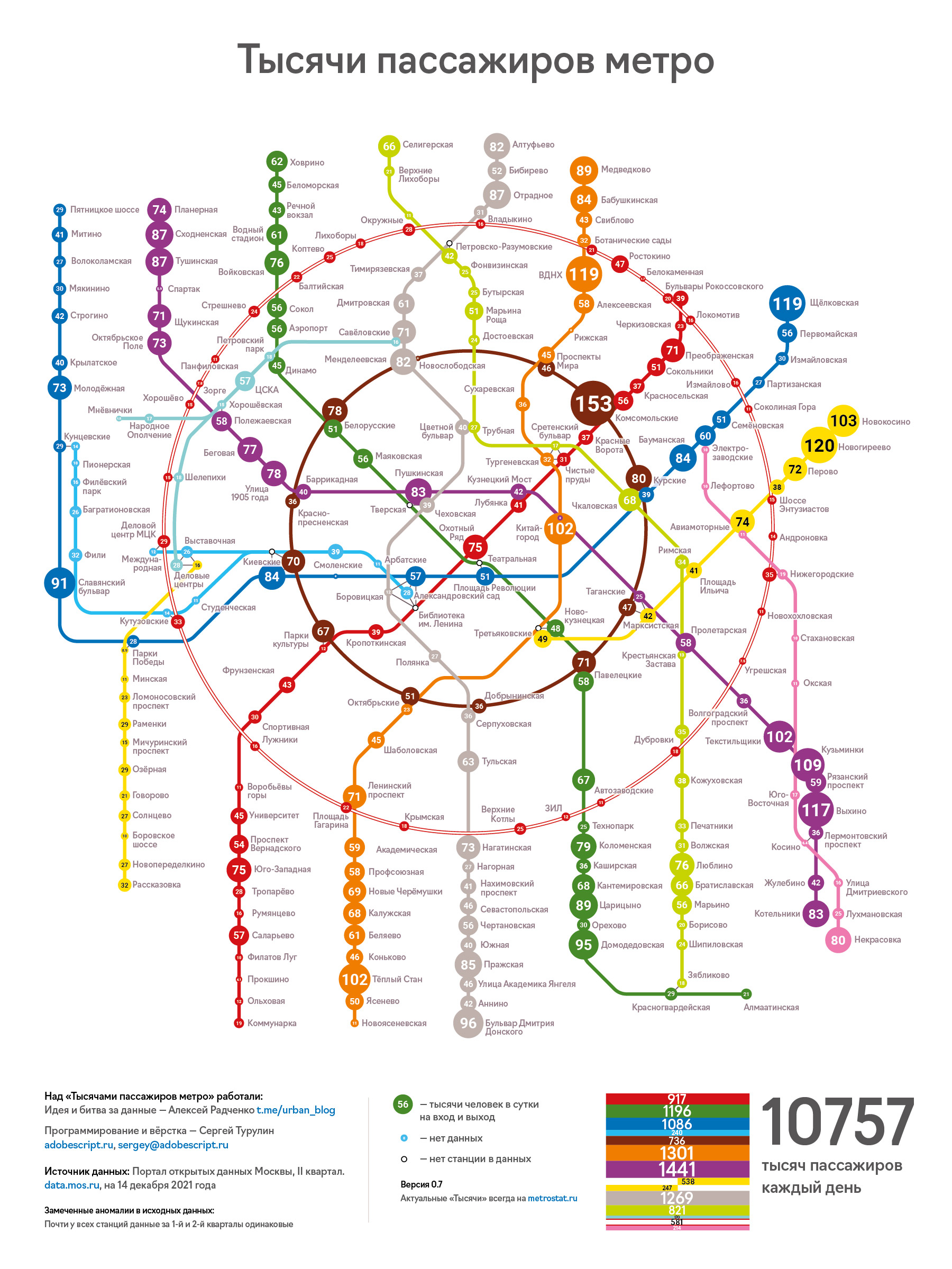
Открыть или скачать в высоком разрешениии png-файл, открыть или скачать в высоком разрешениии pdf-файл.
{kind=link}
Что дальше?
Во-первых, мы хотим регулярно выпускать версии по новым опубликованным данным, чтобы сравнивать разные периоды.
Во-вторых, помимо пассажирских потоков на станциях можно попробовать визуализировать другие данные, которые теперь легко можно отобразить с помощью созданных инструментов.
Если у вас есть идеи, как можно ещё применить этот механизм, пишите мне на почту sergey@adobescript.ru. Обсудим.
Если материал показался вам интересным, подписывайтесь на мой канал про автоматизацию дизайна AdobeScript и на канал о жизни и работе в большом городе Бургомистр.